Create a Smart Python Transform
In this guide, we'll build a Smart Python Transform that uses the reshape="map" option to apply custom per-partition transformations for optimized processing.
Prerequisites
- Ascend Flow
Create a Transform
You can create a Transform in two ways: through the form UI or directly in the Files panel.
- Using the Component Form
- Using the Files Panel
- Double-click the Flow where you want to add your Transform
- Right-click on an existing component (typically a Read component or another Transform) that will provide input data
- Select Create Downstream → Transform
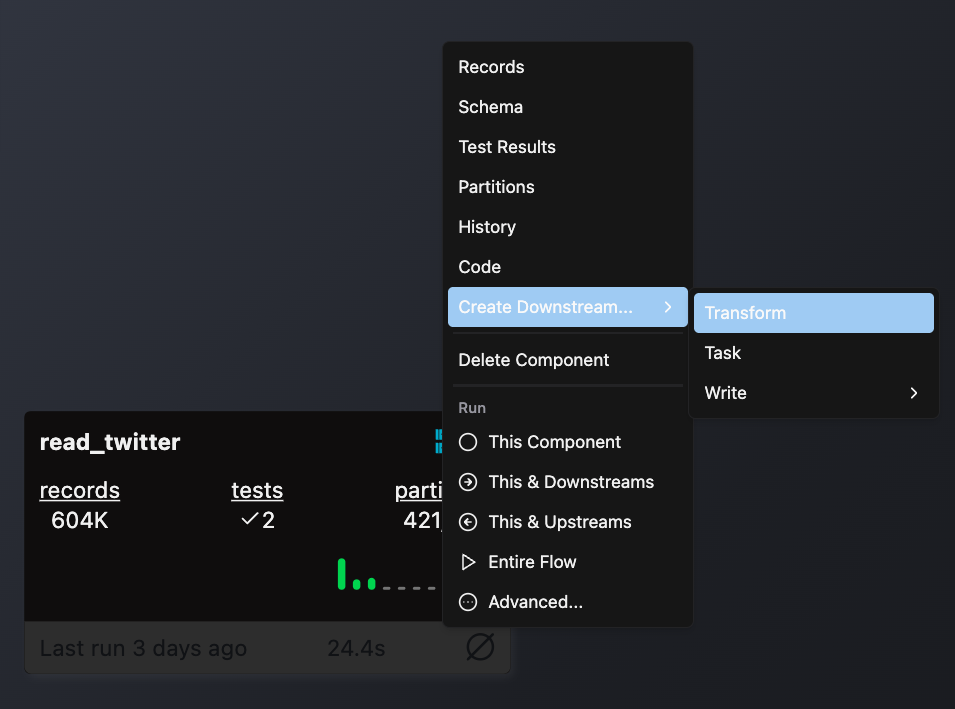
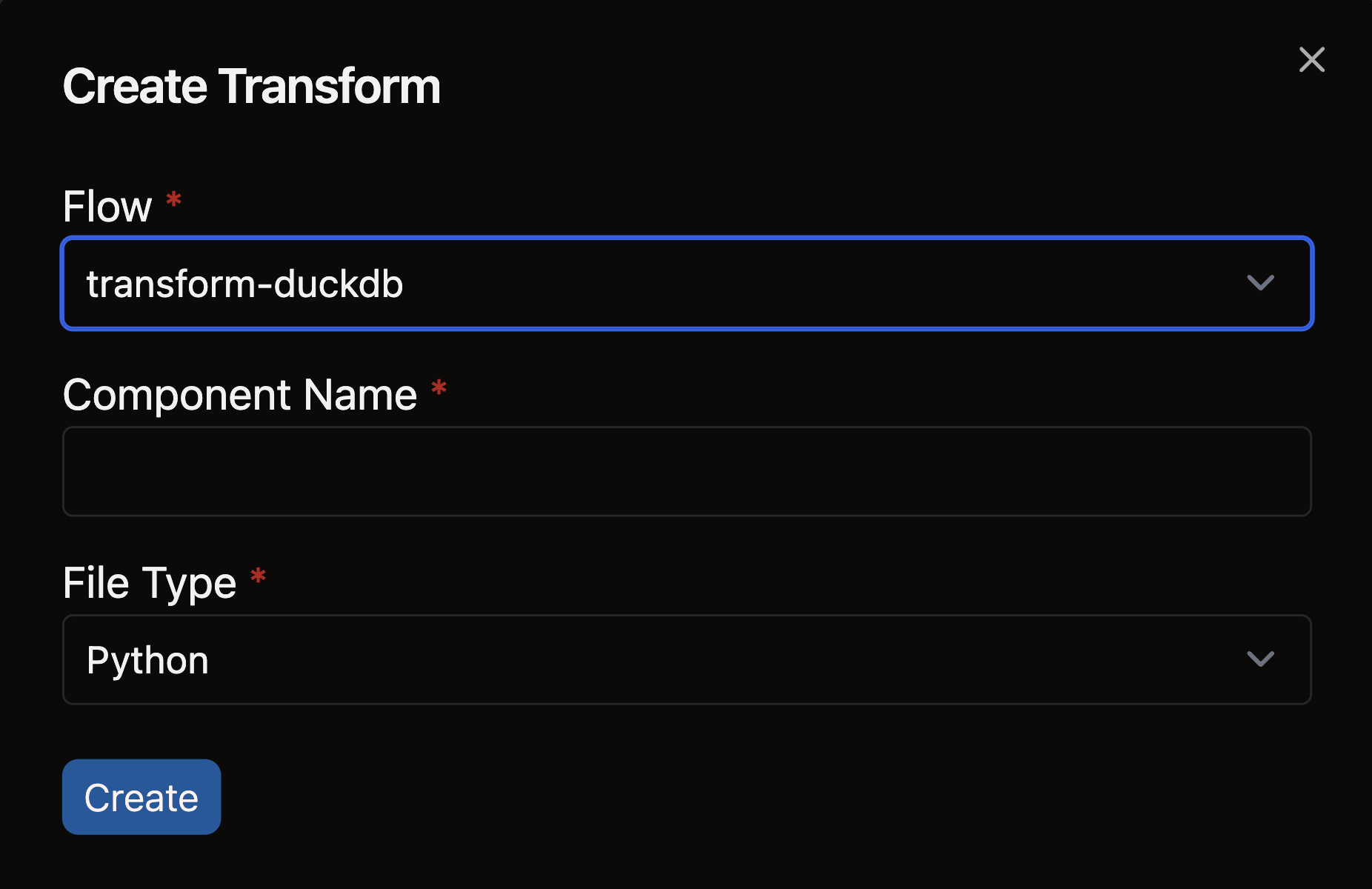
- Complete the form with these details:
- Select your Flow
- Enter a descriptive name for your Transform (e.g.,
sales_aggregation) - Choose the appropriate file type for your Transform logic
- Open the files panel in the top left corner
- Navigate to and select your desired Flow
- Right-click on the components directory and choose New file
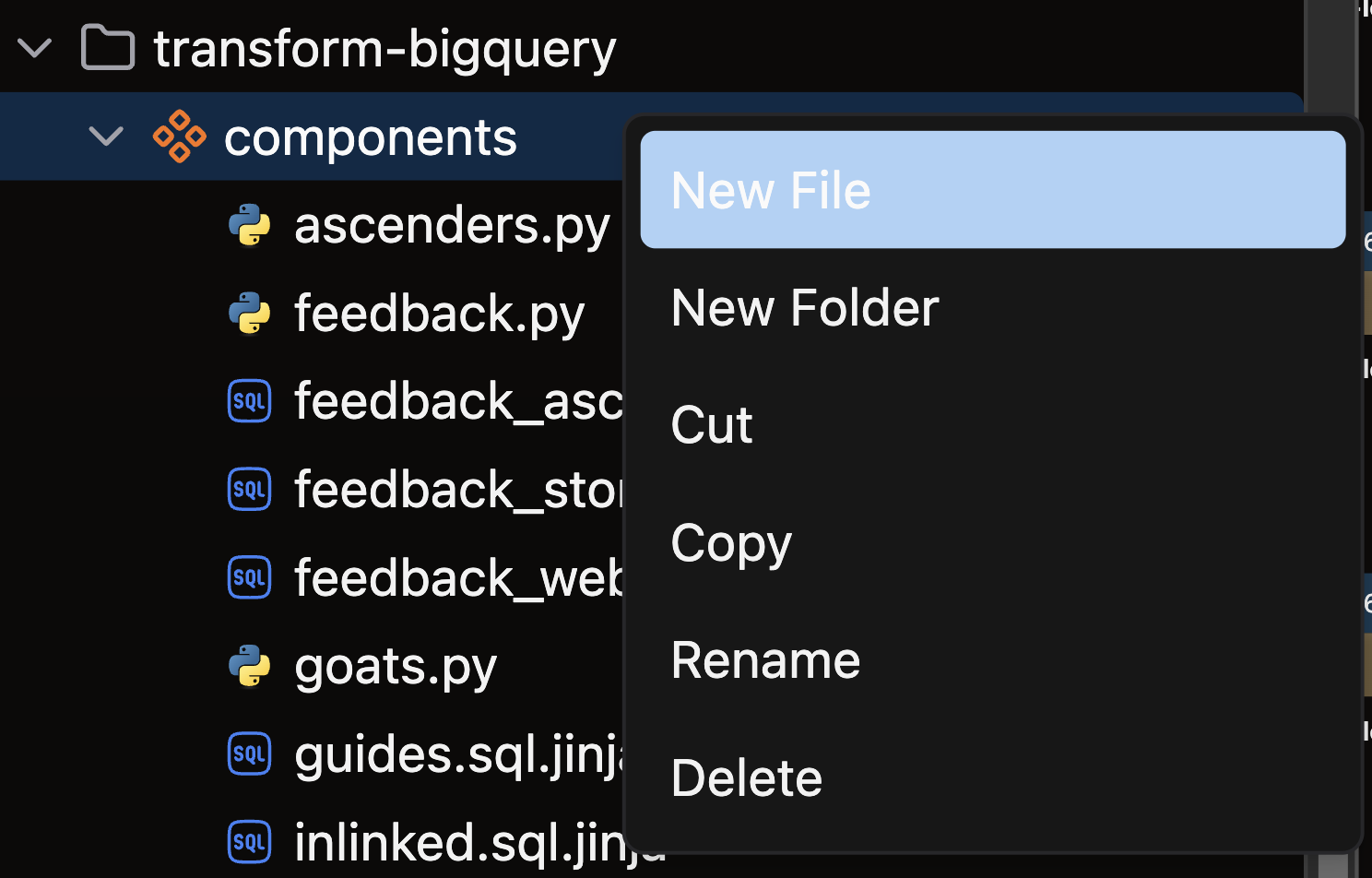
- Name your file with a descriptive name that reflects its purpose (e.g.,
sales_aggregation) - Choose the appropriate file extension based on your Transform type:
.pyfor Python Transforms.sqlfor SQL Transforms
Create your Python Transform
Smart Python Transforms allow you to process data partition-by-partition for more efficient data handling. There are two main approaches:
- Using upstream Partitions
- Using timestamps
Structure using upstream Partitions
-
Import necessary packages:
- Import Ascend resources like
transform,ref, and optionallytest - Import any required data processing libraries (like
ibisin this example)
- Import Ascend resources like
-
Apply the
@transform()decorator with:inputs: Include a primary input withreshape="map"to enable partition-wise processing- Configure additional inputs with
partition_bindingto establish relationships between partitions
-
Define your transform function:
- Create a function that processes each partition independently
- Utilize the context parameter for partition-specific information
-
Process and return data:
- Apply your transformation logic to each partition
- Return the processed data for each partition
Example
smart_transform_upstream.py
"""
Example of a Smart Python Transform Component using upstream partitions.
This file demonstrates how to create a transform that uses the reshape="map" option
with upstream partition binding for optimized per-partition processing.
"""
from ascend.resources import ref, test, transform
from ibis import ir
@transform(
inputs=[ref("primary_data", reshape="map"), ref("join_data", partition_binding="join_key_value = {{ ref('primary_data') }}.join_key")],
tests=[test("count_equal", count=16)], # 4 rows from join_data for each of 4 output partitions
)
def partition_binding(primary_data: ir.Table, join_data: ir.Table, context) -> ir.Table:
"""
Process data using partition binding to efficiently join related partitions.
This function demonstrates how to use partition binding to join data across partitions.
Since we are binding join_data to primary_data on the join_key_value, we should get
multiple partitions from join_data for each output partition processed.
Args:
primary_data: The main partitioned dataset
join_data: Additional data bound to primary_data partitions
context: Component execution context
Returns:
Processed join_data for the current partition
"""
# Assert that we received the expected amount of data for this partition
# This is to verify that partition binding is working as expected
assert join_data.count().execute() == 4
# In a real implementation, you would perform transformation logic here
# For this example, we're simply returning the bound data
return join_data
Structure using Timestamps
-
Import necessary packages:
- Import Ascend resources like
transform,ref, and optionallytest
- Import Ascend resources like
-
Apply the
@transform()decorator with:inputs: Include your input withreshape="map"for timestamp-based partitioning- Add optional tests to validate partition behavior
-
Define your transform function:
- Create a function that can handle time-series partitioned data
- Process each timestamp-based partition independently
-
Process and return data:
- Apply your transformation logic to each time-based partition
- Return the processed data with the same partition structure
Example
smart_transform_timestamps.py
"""
Example of a Smart Python Transform Component using timestamps.
This file demonstrates how to create a transform that uses the reshape="map" option
with time-series data for timestamp-based partition processing.
"""
from ascend.resources import ref, test, transform
@transform(
inputs=[ref("time_series_data", reshape="map")],
tests=[test("count_distinct_equal", column="_ascend_partition_uuid", count=30)],
)
def process_time_series(time_series_data, context):
"""
Process time-series data partitions independently.
This function demonstrates how to process timestamp-partitioned data using
the reshape="map" option. Each partition (typically representing a time period)
will be processed separately.
Args:
time_series_data: The partitioned time-series dataset
context: Component execution context containing partition information
Returns:
Processed time-series data for the current partition
"""
# You can access partition information with context.partition_key
# This would let you know which time period you're processing
# In a real implementation, you would perform time-series specific
# transformation logic here - such as aggregations, calculations or filtering
# For this example, we're simply passing the data through
return time_series_data
🎉 Congratulations! You've successfully created a Smart Python Transform in Ascend.