Create an incremental SQL transform
In this guide, we'll build an incremental SQL transform that processes only new or changed data to significantly improve pipeline performance.
Prerequisites
- Ascend Flow
Create a Transform
You can create a Transform in two ways: through the form UI or directly in the Files panel.
- Using the Component Form
- Using the Files Panel
- Double-click the Flow where you want to add your Transform
- Right-click on an existing component (typically a Read component or another Transform) that will provide input data
- Select Create Downstream → Transform
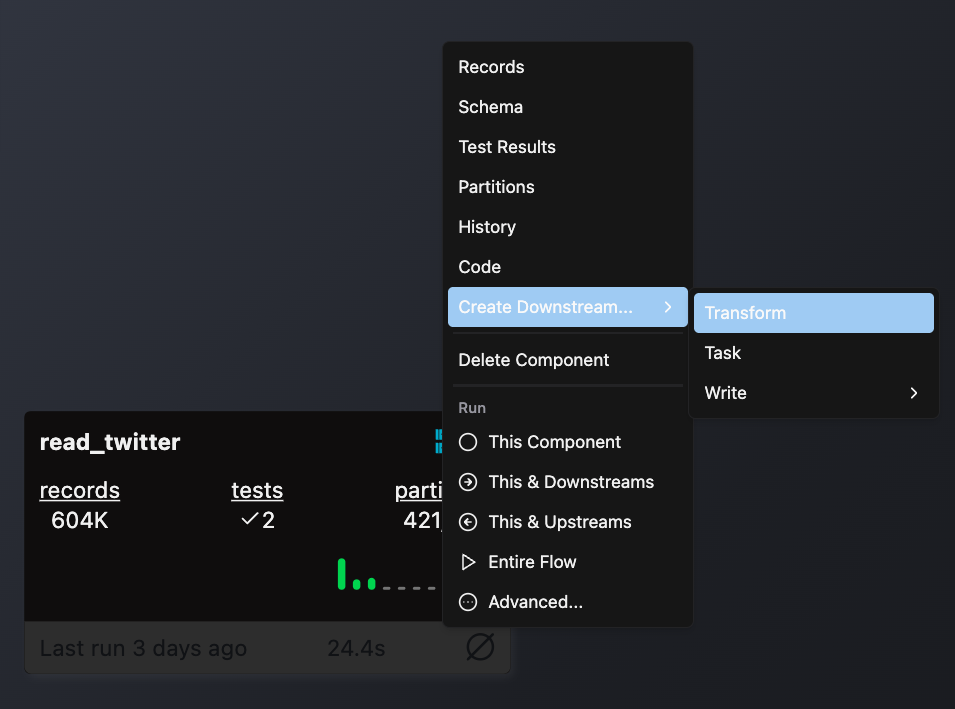
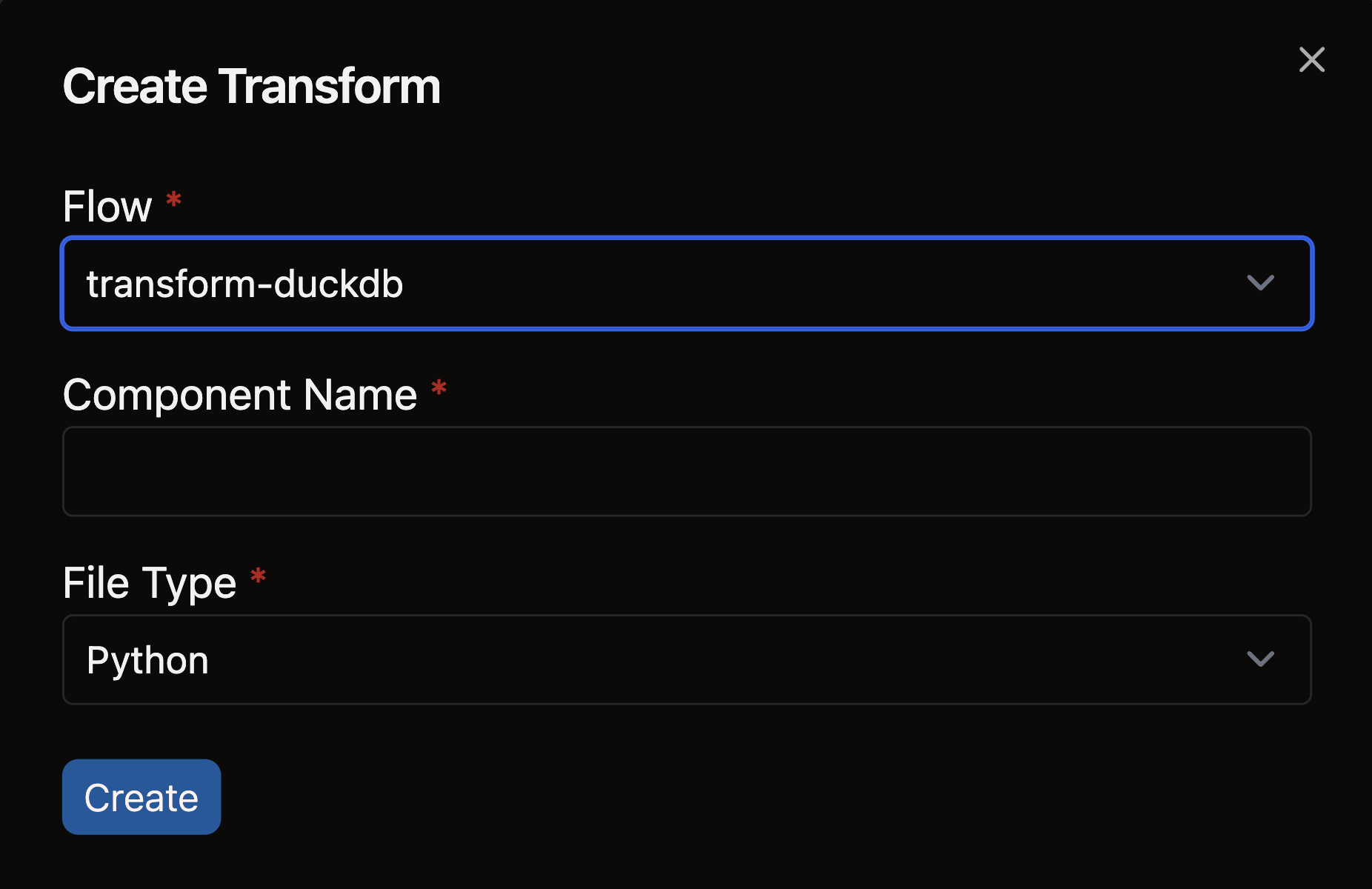
- Complete the form with these details:
- Select your Flow
- Enter a descriptive name for your Transform (e.g.,
sales_aggregation) - Choose the appropriate file type for your Transform logic
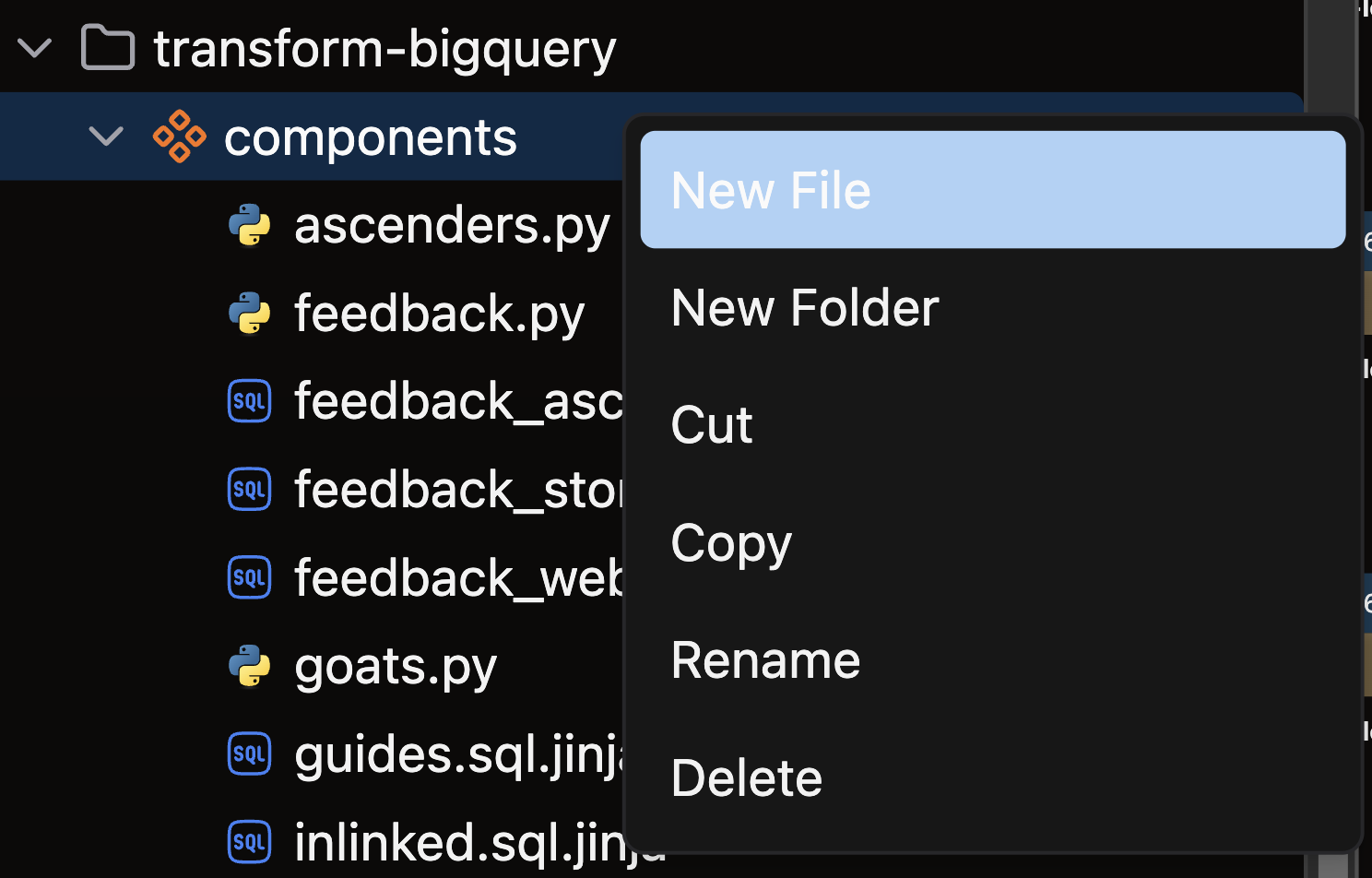
- Open the files panel in the top left corner
- Navigate to and select your desired Flow
- Right-click on the components directory and choose New file
- Name your file with a descriptive name that reflects its purpose (e.g.,
sales_aggregation) - Choose the appropriate file extension based on your Transform type:
.pyfor Python Transforms.sqlfor SQL Transforms
Writing your incremental transform
Incremental SQL transforms optimize data processing by focusing exclusively on new or changed data since the previous run. This approach dramatically reduces processing time and resource usage, especially for large and continuously growing datasets.
Configure incremental processing
To create an incremental SQL transform, include these parameters in the jinja config block above your transform logic:
materialized: "incremental" - Enables incremental processing modeincremental_strategy: "merge" - Defines how new and existing data are combinedunique_key: A comma-separated string of column names that identify unique records for insert/update operations
{{
config(
materialized="incremental",
incremental_strategy="merge",
unique_key="key"
)
}}
SELECT * FROM {{ ref("incrementing_read_connector") }}
When this transform runs, Ascend executes your SQL query and performs an "upsert" operation (insert + update) based on the unique key:
- Records with new unique key values are inserted as new rows
- Records with existing unique key values update the corresponding rows
Control column updates
You can fine-tune which columns get updated during merge operations with these optional parameters:
merge_update_columns: Specifies which columns to update (all other columns remain unchanged)merge_exclude_columns: Lists columns to exclude from updates (all other columns are updated)
These parameters are mutually exclusive, so choose the approach that best fits your use case.
Example: Preserving original timestamps
This example shows how to preserve creation timestamps while updating other fields:
{{
config(
materialized="incremental",
incremental_strategy="merge",
unique_key="key",
merge_exclude_columns=["record_first_inserted_ts"]
)
}}
SELECT *, CURRENT_TIMESTAMP() AS record_first_inserted_ts
FROM {{ ref("incrementing_read_connector") }}
In this configuration, when a row is updated, the original record_first_inserted_ts value is preserved, maintaining the record's creation history while updating all other fields with new values.
🎉 Congratulations! You just created your first incremental SQL transform in Ascend!