Create a smart SQL transform
In this guide, we'll build smart SQL transforms that leverage advanced partitioning strategies to optimize processing performance and resource utilization.
Prerequisites
- Ascend Flow
Create a Transform
You can create a Transform in two ways: through the form UI or directly in the Files panel.
- Using the Component Form
- Using the Files Panel
- Double-click the Flow where you want to add your Transform
- Right-click on an existing component (typically a Read component or another Transform) that will provide input data
- Select Create Downstream → Transform
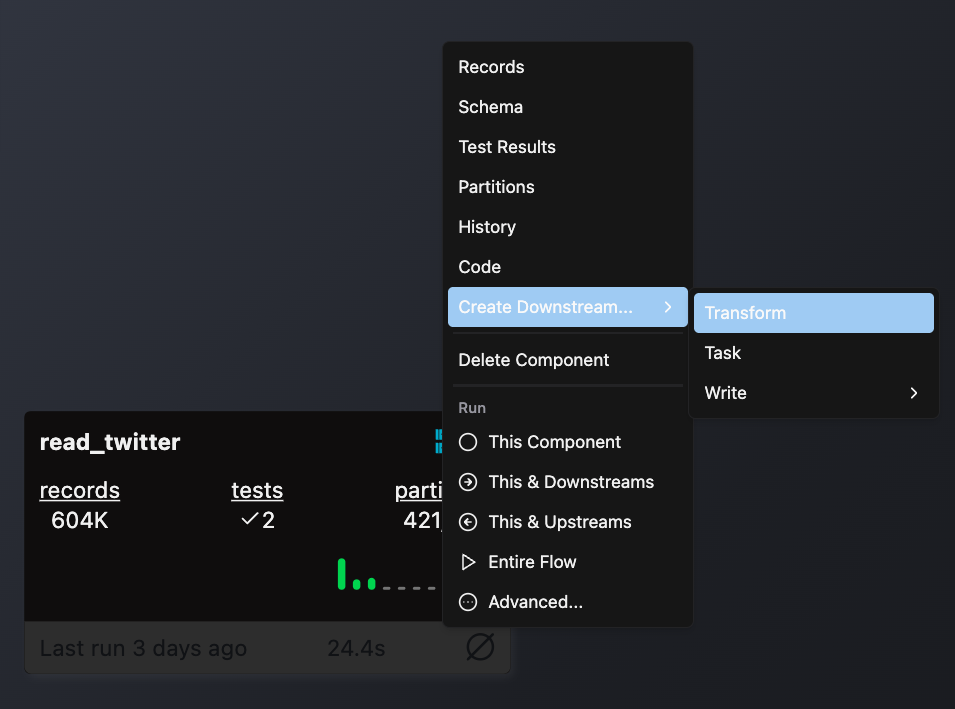
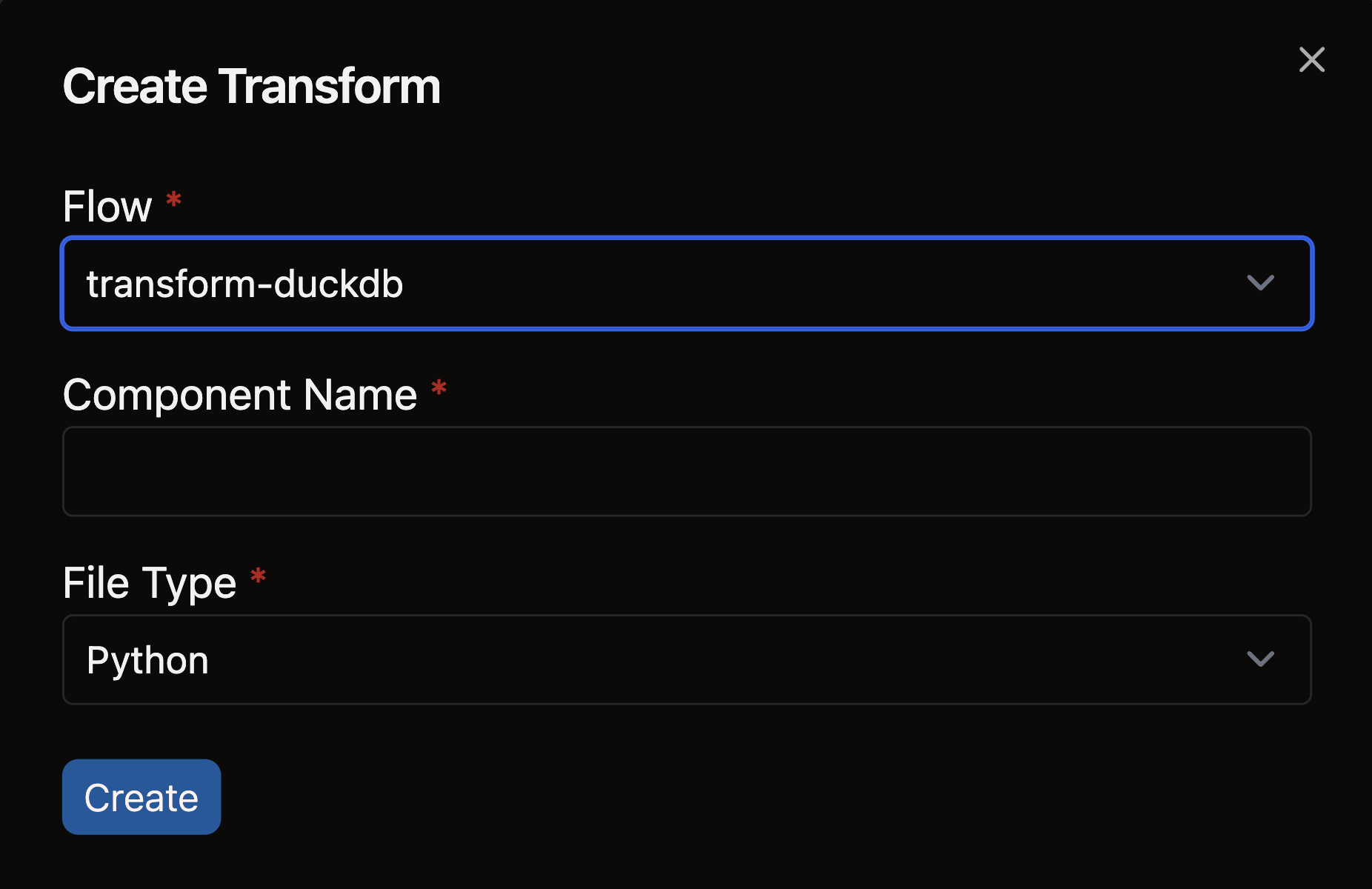
- Complete the form with these details:
- Select your Flow
- Enter a descriptive name for your Transform (e.g.,
sales_aggregation) - Choose the appropriate file type for your Transform logic
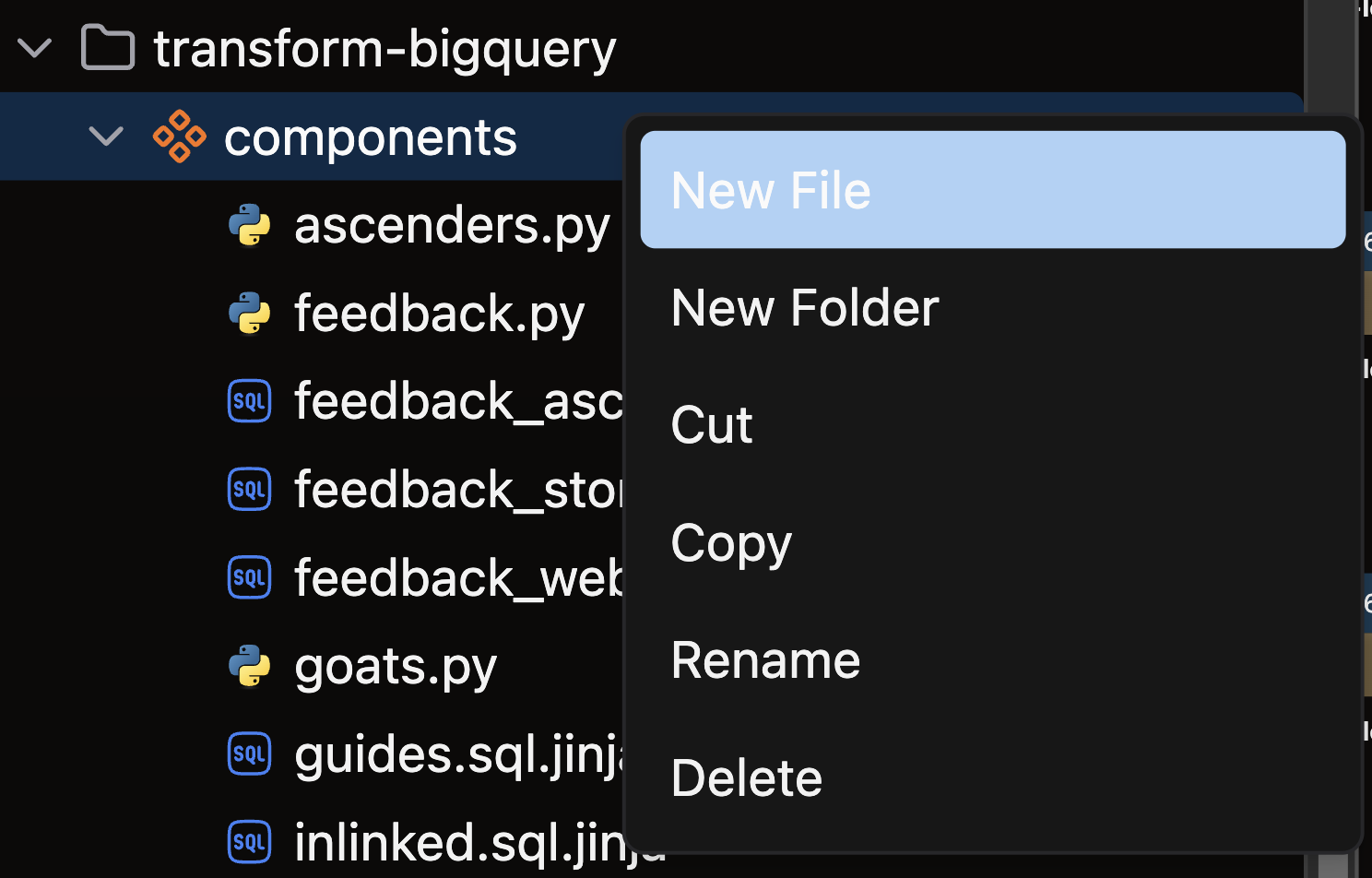
- Open the files panel in the top left corner
- Navigate to and select your desired Flow
- Right-click on the components directory and choose New file
- Name your file with a descriptive name that reflects its purpose (e.g.,
sales_aggregation) - Choose the appropriate file extension based on your Transform type:
.pyfor Python Transforms.sqlfor SQL Transforms
Writing your smart transform
Smart SQL transforms enable partition-based data processing to dramatically improve performance for large datasets. Choose between two powerful partitioning approaches based on your specific needs:
- Daily partitioning: Uses time-based partitioning with the
reshapeparameter to efficiently process data by date intervals - Smart partitioning: Uses
reshape="map"to automatically adopt and optimize processing based on the existing partition structure of upstream components
- Daily Partitioning
- Smart Partitioning
Daily partitioning
Time-based partitioning divides your data processing by date intervals, allowing parallel execution and focused processing of specific time periods.
Structure your SQL code with a time dictionary in the reshape parameter, specifying the date column and granularity:
SELECT * FROM
{{ ref('epl_results', reshape={'time': {'column': 'DateTime', 'granularity': 'day'}}) }}
{{ with_test("count_equal", count=11113) }}
{{ with_test("count_distinct_equal", column="_ascend_partition_uuid", count=3031) }}
This creates a separate partition for each day in the DateTime column, enabling concurrent processing and more efficient resource utilization.
Smart partitioning
Smart partitioning intelligently inherits the partitioning scheme from upstream components, maintaining data locality and minimizing unnecessary data movement.
Simply use reshape="map" to automatically adopt the upstream partitioning strategy:
SELECT * FROM {{ ref("multi_partition_generic", reshape="map")}}
{{ with_test("count_distinct_equal", column="_ascend_partition_uuid", count=3) }}
This approach is particularly valuable when working with pre-partitioned data sources, as it preserves the existing partition boundaries while applying your transformations.
🎉 Congratulations! You just created your first smart SQL transform in Ascend!