Incremental Python Read
In this guide, we'll build an Incremental Python Read Component that ingests only new or updated records by leveraging Ascend's Incremental strategy.
Prerequisites
- Ascend Flow
Create a new Component
From your Workspace Super Graph view, follow these steps to create your Component:
- Form
- Files panel
- Double-click the Flow where you want to create your Component
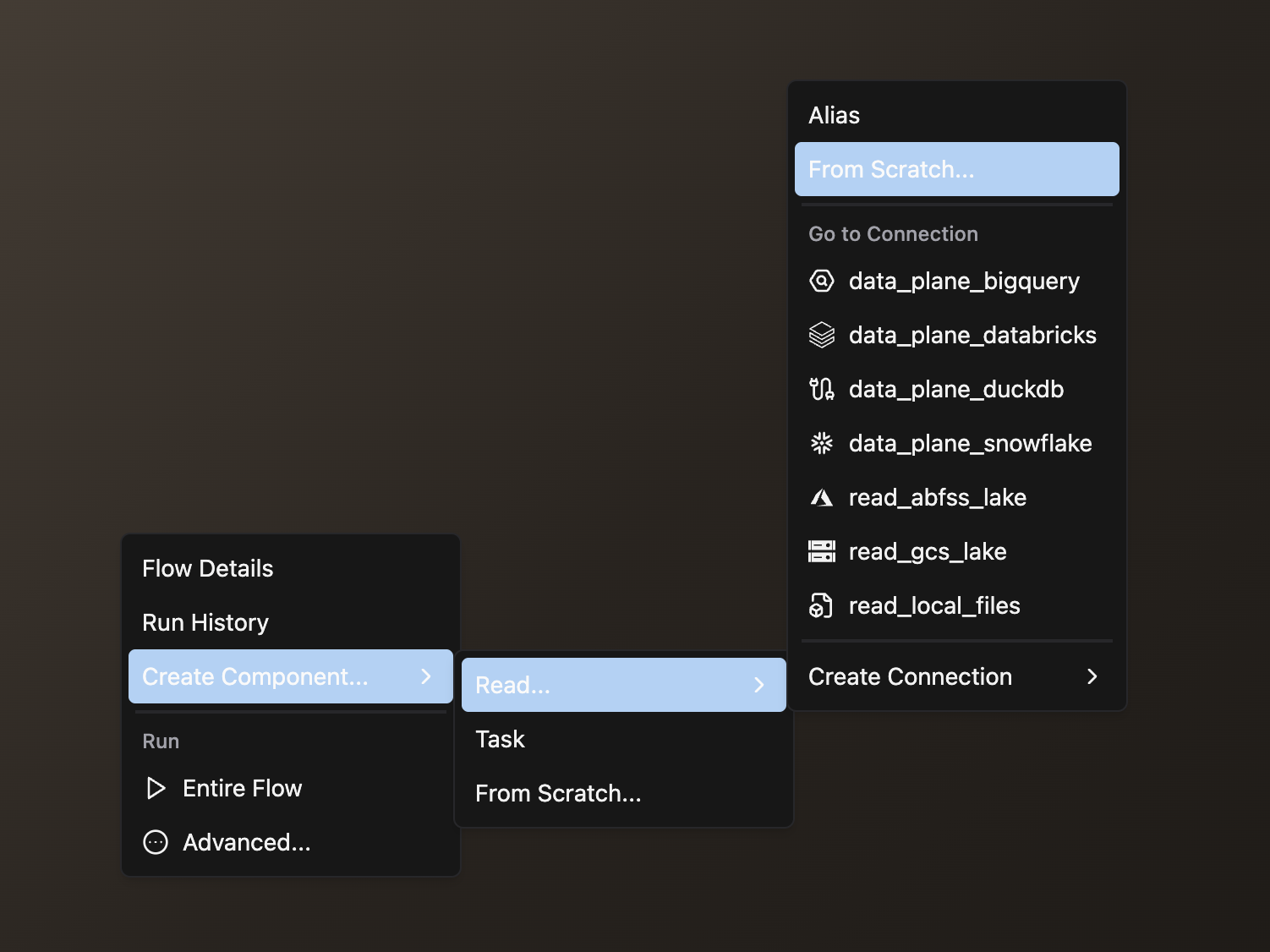
- Right-click anywhere in the Flow Graph
- Hover over Create Component, then over Read in the expanded menu, and click From Scratch
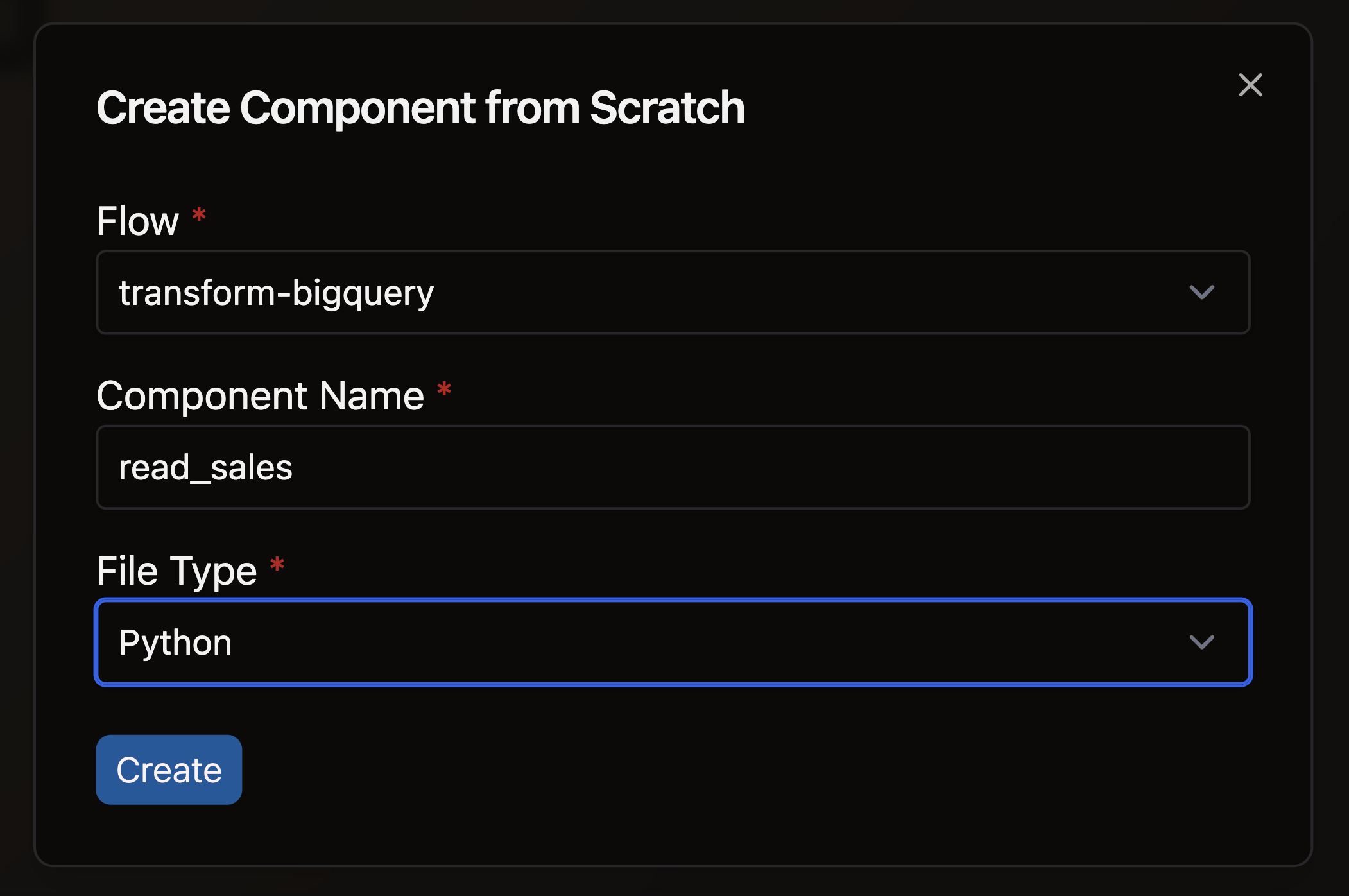
- Complete the form with these details:
- Select your Flow
- Enter a descriptive Component Name like
read_sales - Select Python as your file type
- Open the files panel in the top left corner
- Navigate to and select your desired Flow
- Right-click on the components directory and choose New file
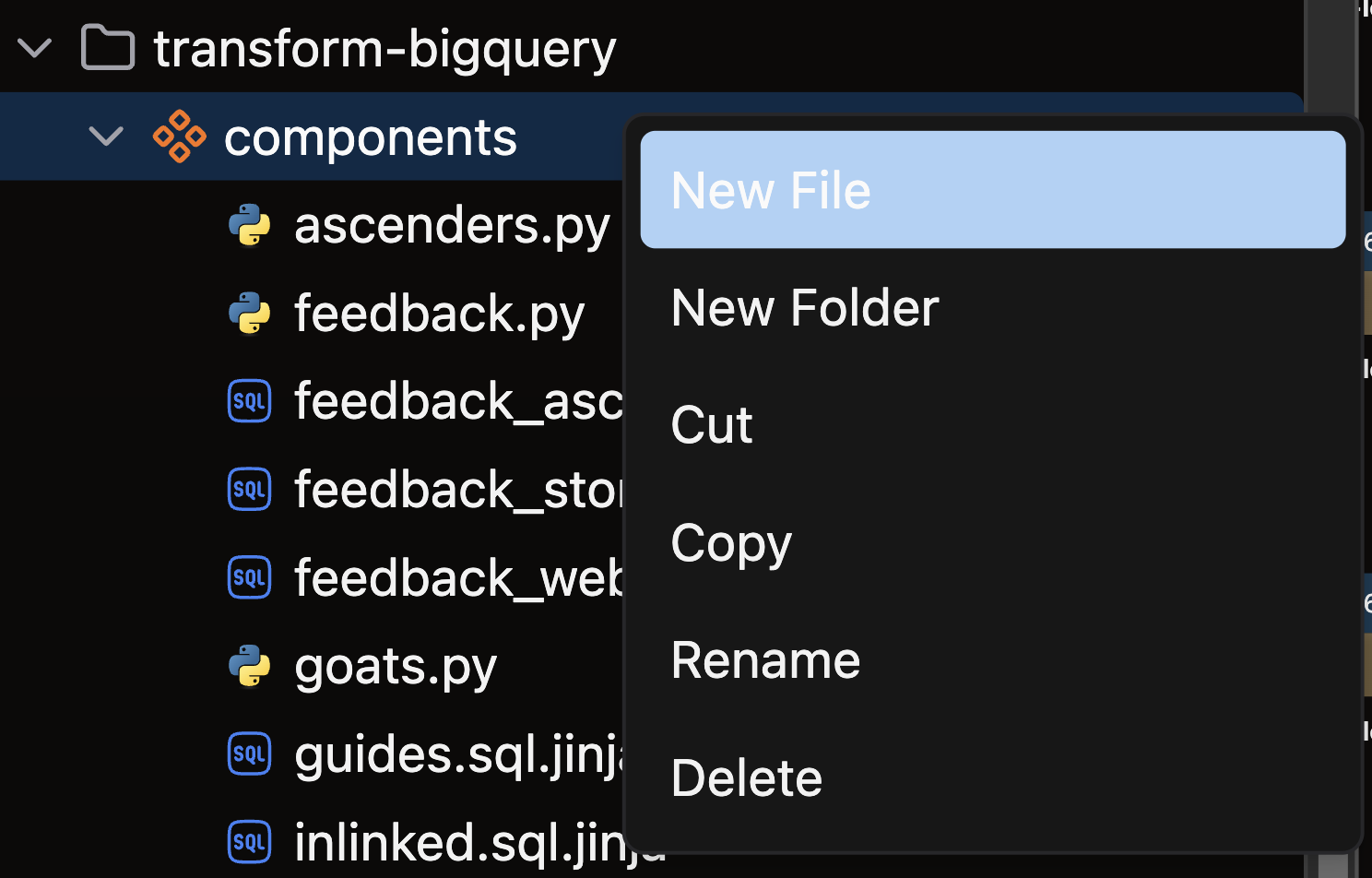
- Name your file with a descriptive name like
read_sales.pyand press enter
Create your Incremental Python Read Component
Structure your Incremental Python Read Component following this pattern, based on our Otto's Expeditions Project:
-
Import necessary packages: Include Ascend resources (
read), context handlers (ComponentExecutionContext), data processing libraries (likePolarsorpandas), and logging utilities (log) -
Apply the
@read()decorator with incremental configuration:- Set
strategy="incremental"to enable incremental processing - Choose
incremental_strategy="merge"or"append"based on your data needs - Specify
unique_keyfor merge operations - Set
on_schema_change="sync_all_columns"to handle schema evolution
- Set
-
Define your incremental read function: Implement logic that filters data based on previous state
-
Return structured data: Return the processed data as a dataframe or table
The @read() decorator integrates your function into Ascend's stateful execution framework, automatically managing incremental state and schema updates.
Choose an Incremental Strategy
Ascend offers two incremental strategies: merge and append. Choose based on your data requirements:
| Strategy | Description | When to Use | Required parameters |
|---|---|---|---|
| Merge | Updates existing records based on a key and inserts new ones | For data that can be updated (user profiles, product info) | unique_key |
| Append | Simply adds new data to existing dataset | For immutable data (logs, events) | None |
For detailed explanations, see our incremental processing reference guide.
Merge strategy example
This example demonstrates the merge incremental strategy using our Otto's Expeditions Project:
Append strategy example
This example demonstrates the append incremental strategy with timestamp-based filtering:
For more examples and advanced options, see our reference guide.
🎉 Congratulations! You've successfully created an Incremental Python Read Component in Ascend.