Simple SQL Transform
In this guide, we'll build a Simple SQL Transform that efficiently processes entire datasets using standard SQL.
Prerequisites
- Ascend Flow
Create a Transform
You can create a Transform in two ways: through the form UI or directly in the Files panel.
- Form
- Files panel
- Double-click the Flow where you want to add your Transform
- Right-click on an existing component (typically a Read component or another Transform) that will provide input data
- Select Create Downstream → Transform
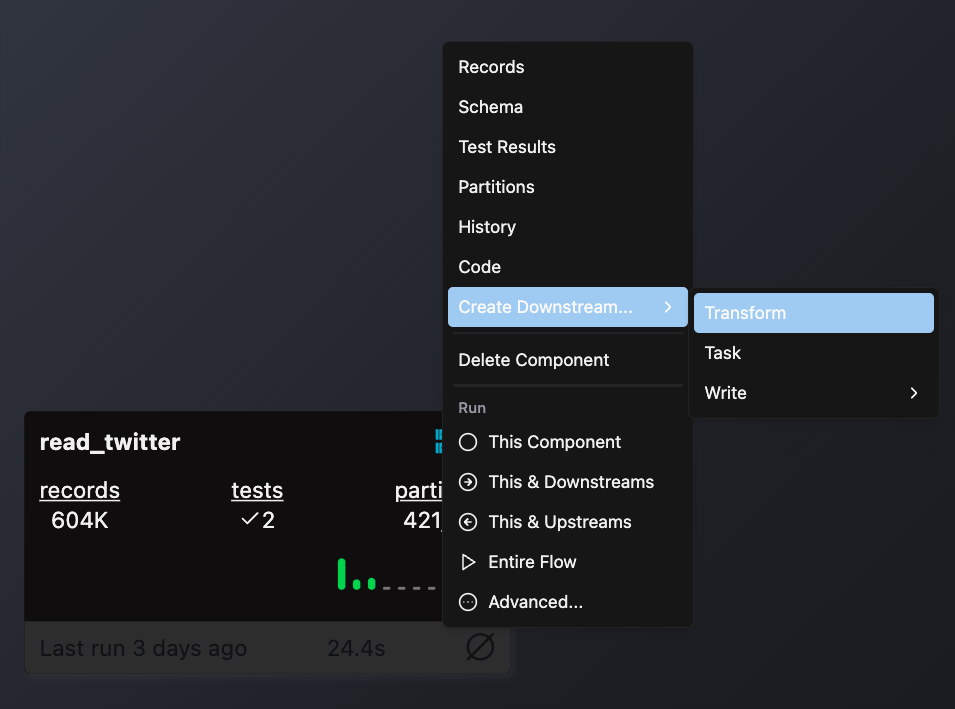
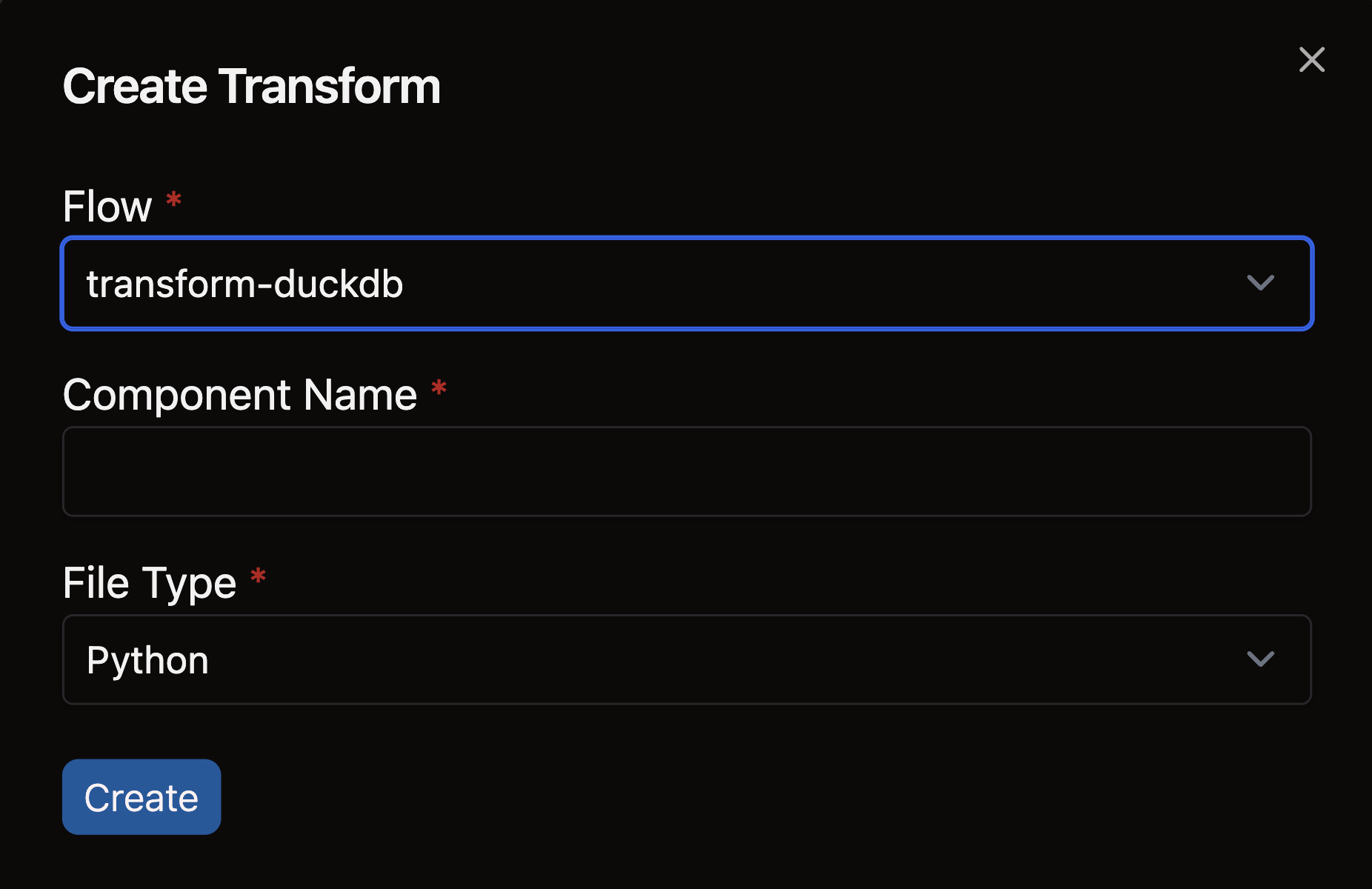
- Complete the form with these details:
- Select your Flow
- Enter a descriptive name for your Transform (e.g.,
sales_aggregation) - Choose the appropriate file type for your Transform logic
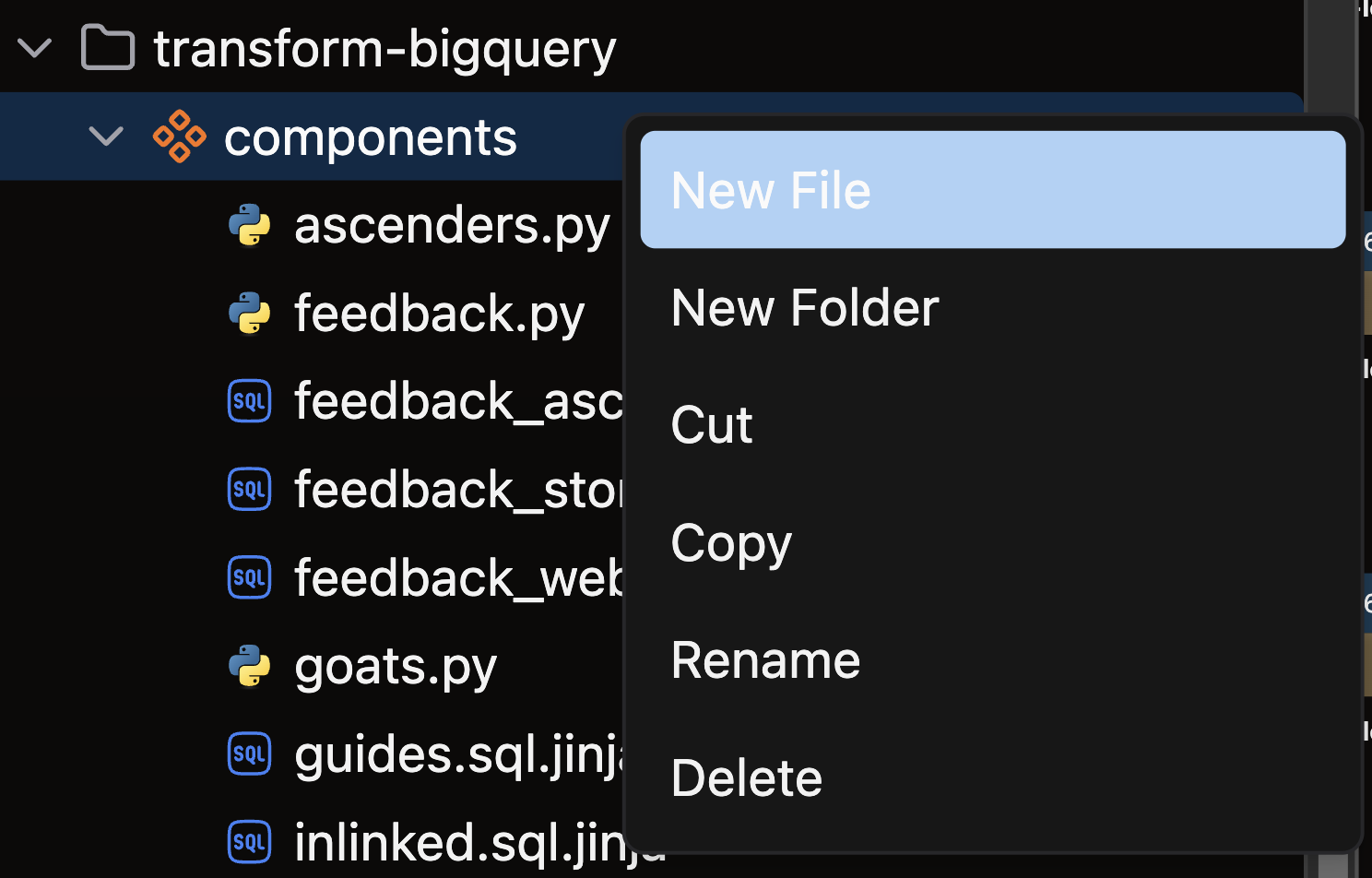
- Open the files panel in the top left corner
- Navigate to and select your desired Flow
- Right-click on the components directory and choose New file
- Name your file with a descriptive name that reflects its purpose (e.g.,
sales_aggregation) - Choose the appropriate file extension based on your Transform type:
.pyfor Python Transforms.sqlfor SQL Transforms
Create your Simple SQL Transform
Simple SQL Transforms let you apply familiar SQL operations to your data while leveraging Ascend's powerful orchestration capabilities. These transforms execute standard SQL queries against referenced input Components.
Basic structure
Structure your SQL code using the ref function to reference upstream data sources, which can be either Read Components or other Transforms.
Minimal example
SELECT * FROM {{ ref("<YOUR-UPSTREAM-COMPONENT-NAME>") }}
Practical example
SELECT
cabs.*,
pickup_zones.Borough AS pickup_borough,
pickup_zones.Zone AS pickup_zone,
pickup_zones.service_zone AS pickup_service_zone,
dropoff_zones.Borough AS dropoff_borough,
dropoff_zones.Zone AS dropoff_zone,
dropoff_zones.service_zone AS dropoff_service_zone
FROM {{ ref('all_cabs') }} AS cabs
LEFT OUTER JOIN {{ ref('taxi_zone_lookup') }} AS pickup_zones
ON cabs.pickup_location_id = pickup_zones.LocationID
LEFT OUTER JOIN {{ ref('taxi_zone_lookup') }} AS dropoff_zones
ON cabs.dropoff_location_id = dropoff_zones.LocationID
Advanced Transform features
Ascend offers powerful features that can significantly improve your data pipeline's performance, reliability, and maintainability.
Data partitioning
By default, transforms process the entire dataset as a single unit. However, you can dramatically improve performance by partitioning your data into smaller chunks that process in parallel. Enable this by adding partition_by and granularity parameters to the ref function.
For example, to process taxi trip data by day:
SELECT
cabs.*,
pickup_zones.Borough AS pickup_borough,
pickup_zones.Zone AS pickup_zone,
pickup_zones.service_zone AS pickup_service_zone,
dropoff_zones.Borough AS dropoff_borough,
dropoff_zones.Zone AS dropoff_zone,
dropoff_zones.service_zone AS dropoff_service_zone
/* Partition daily by pickup-datetime column */
FROM {{ ref('all_cabs', partition_by='pickup_datetime', granularity='day') }} AS cabs
LEFT OUTER JOIN {{ ref('taxi_zone_lookup') }} AS pickup_zones
ON cabs.pickup_location_id = pickup_zones.LocationID
LEFT OUTER JOIN {{ ref('taxi_zone_lookup') }} AS dropoff_zones
ON cabs.dropoff_location_id = dropoff_zones.LocationID
When executed, Ascend partitions the input data by day based on the pickup_datetime column and processes each partition concurrently, significantly accelerating processing for large datasets.
For more on partitioning strategies, see our guides on advanced partitioning and incremental transforms.
Schema evolution handling
You can define how your transform adapts to schema changes by adding the on_schema_change option to the config block. This is particularly valuable in environments where source data schemas evolve frequently.
This example shows how to automatically incorporate new columns:
Data validation testing
Integrate automated data quality checks using the with_test function to validate transform outputs. These tests execute whenever the transform runs, ensuring data meets your quality requirements.
Here we validate that:
- The
vendor_idcolumn contains no null values - The output contains exactly 2,912,193 rows
For a complete list of available tests, see our data quality testing reference.
🎉 Congratulations! You just created your first Simple SQL Transform in Ascend!