Create a Simple PySpark Transform
This guide shows you how to build a Simple PySpark Transform that processes data without using incremental or smart partitioning strategies.
PySpark is Apache Spark's Python API that enables distributed data processing with Python, allowing you to work with large datasets across a cluster.
Let's keep it Simple!
Note that PySpark is only available to Ascend Instances running on Databricks. Check out our Quickstart to set up a Databricks Instance
Prerequisites
- Ascend Flow
Create a Transform
You can create a Transform in two ways: through the form UI or directly in the Files panel.
- Using the Component Form
- Using the Files Panel
- Double-click the Flow where you want to add your Transform
- Right-click on an existing component (typically a Read component or another Transform) that will provide input data
- Select Create Downstream → Transform
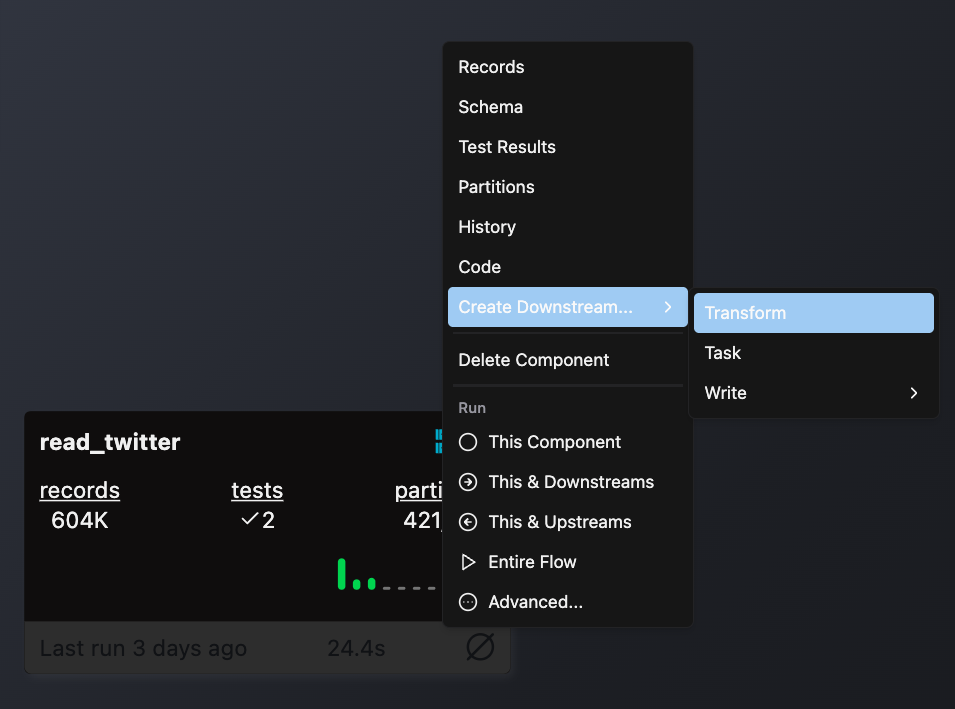
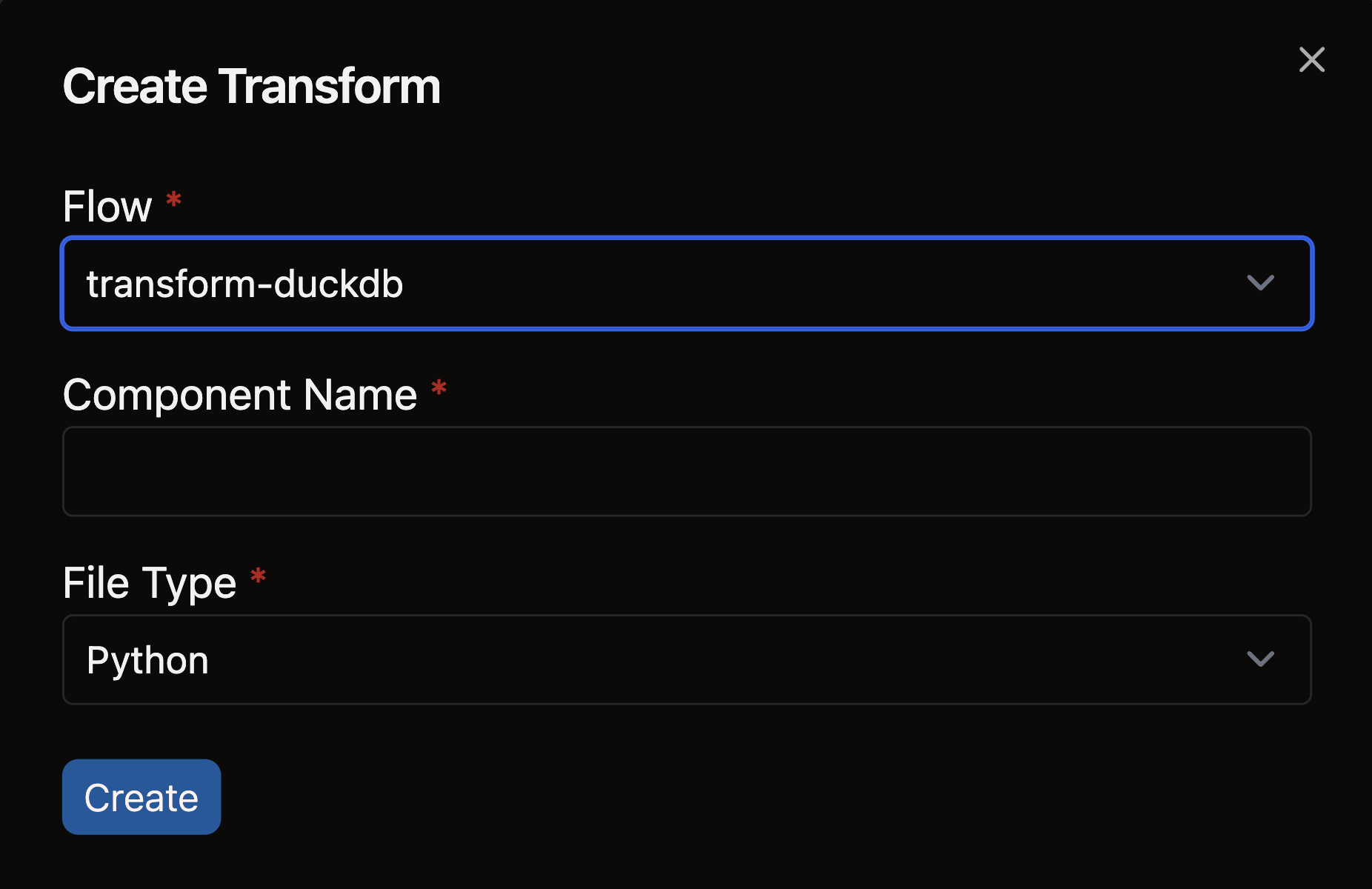
- Complete the form with these details:
- Select your Flow
- Enter a descriptive name for your Transform (e.g.,
sales_aggregation) - Choose the appropriate file type for your Transform logic
- Open the files panel in the top left corner
- Navigate to and select your desired Flow
- Right-click on the components directory and choose New file
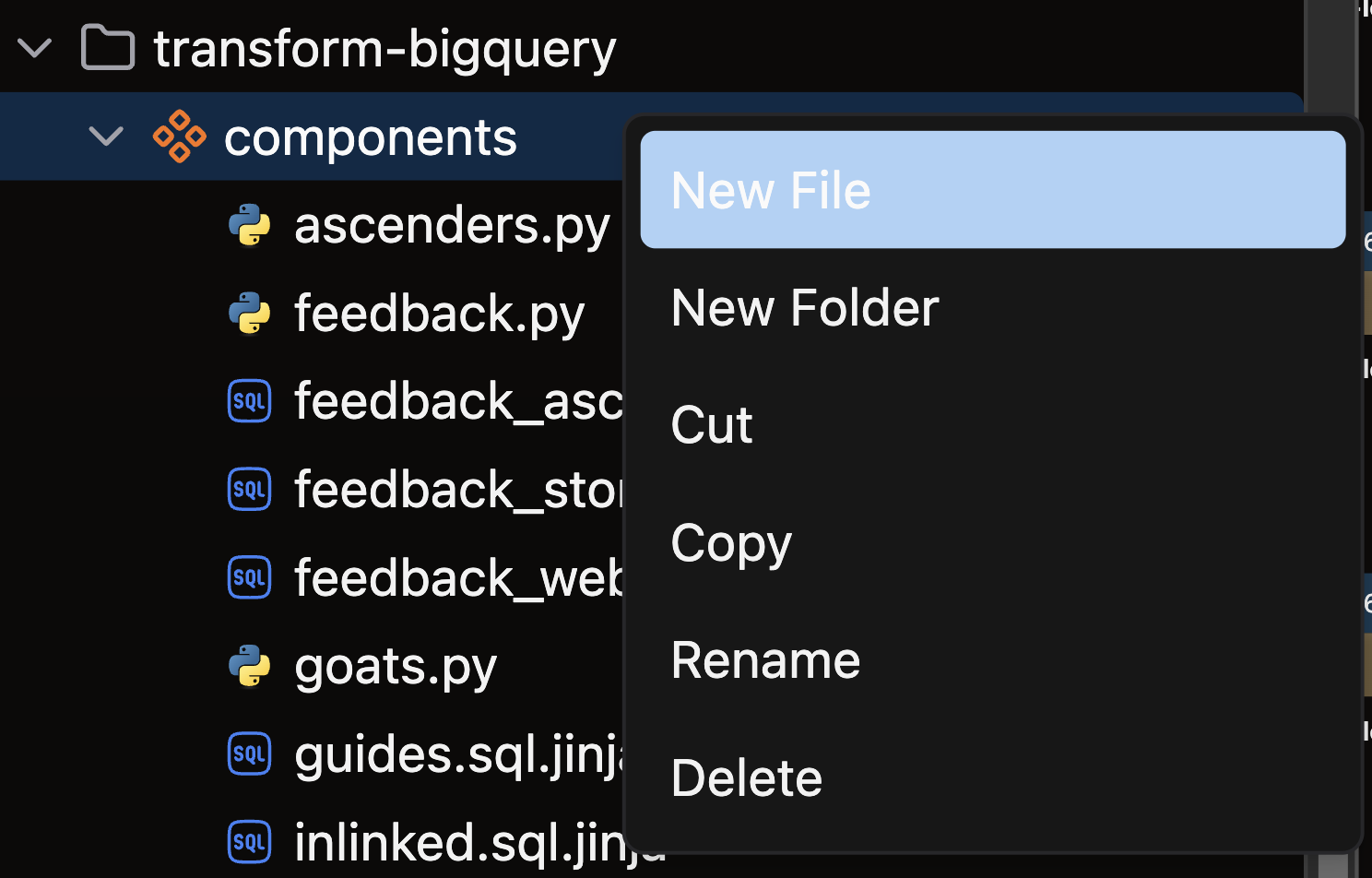
- Name your file with a descriptive name that reflects its purpose (e.g.,
sales_aggregation) - Choose the appropriate file extension based on your Transform type:
.pyfor Python Transforms.sqlfor SQL Transforms
Create your Simple PySpark Transform
This guide walks you through building a Simple PySpark Transform that processes data without using incremental or smart partitioning strategies.
Let's keep it Simple!
Structure your PySpark Transform using these steps:
-
Import required packages:
- Ascend resources (
pyspark,ref) - PySpark objects (
DataFrame,SparkSession)
- Ascend resources (
-
Define your transform function:
- Create a function that processes your input data
- The example below simply returns the data unchanged
-
Apply the
@pyspark()decorator:- Specify your
inputsusing refs - Set
event_timeandcluster_byparameters to control how Spark organizes your data
- Specify your
-
Return structured data:
- Your function must return a DataFrame
The @pyspark() decorator handles all conversions between Spark and Ascend's internal format, allowing your Transform to integrate seamlessly with other Components in your Flow.
Example
Here's a basic example of a PySpark Transform:
from ascend.resources import pyspark, ref
from pyspark.sql import DataFrame, SparkSession
@pyspark(
inputs=[
ref("cab_rides"),
],
event_time="pickup_datetime",
cluster_by=["cab_type"],
)
def cab_rides_simple_pyspark(spark: SparkSession, cab_rides: DataFrame, context):
return cab_rides
Check out our PySpark Transform reference guide for complete parameter options, advanced configurations, and additional examples.
🎉 Congratulations! You've successfully created a Simple PySpark Transform in Ascend.