Schema change
This guide shows you how to implement schema change strategies in your Ascend pipelines to handle evolving data schemas gracefully and maintain robust, resilient Flows.
Ascend uses the Smart schema strategy by default for supported Connection types, while other Connection types default to the fail strategy. For comprehensive information about available strategies, see our concept guide.
Full refresh
To perform a full refresh on an entire Flow:
- Navigate to the Build Info panel and click Run Flow
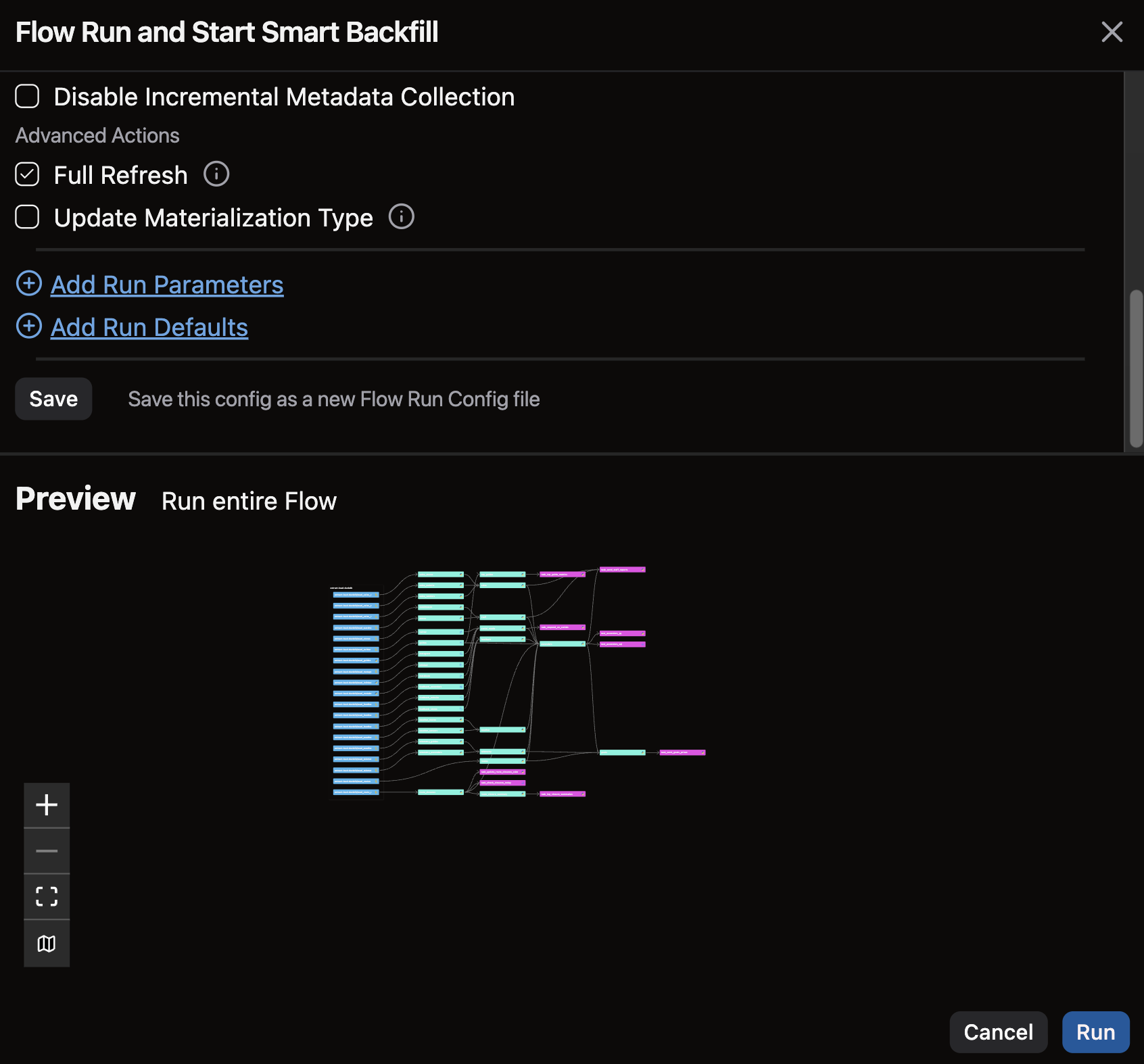
- In the
Run Flowdialog, scroll down to theAdvanced Actionssection and check the box for theFull Refreshoption - Click Run to execute the entire Flow in full-refresh mode
Examples
This section demonstrates how to specify a schema change strategy in different types of Components. By configuring the on_schema_change parameter correctly, you can ensure your data pipelines remain resilient when source schemas evolve.
Incremental Python Read
In this example, an Incremental Read Component specifies the "sync_all_columns" schema change strategy in the @read decorator:
Local File Read Component
This example demonstrates how to configure a local file system Read Component with the ignore schema change strategy:
component:
read:
connection: local_fs
local_file:
path: rc_schema_evolution/
include:
- regex: .*\.csv
parser:
csv:
has_header: true
strategy:
partitioned:
enable_substitution_by_partition_name: false
on_schema_change: ignore
Incremental MySQL Read Component
This example shows an incremental MySQL Read Component configured with the sync_all_columns strategy and merge-based incremental loading:
Incremental Python Transform
The following Python Transform Component uses the on_schema_change parameter to specify how to handle schema changes when running incrementally:
Incremental SQL Transform
This SQL Transform example shows how to configure schema change handling in SQL using the config block:
{{
config(
materialized="incremental",
incremental_strategy="merge",
unique_key="key",
merge_update_columns=["string", "ts"],
on_schema_change="sync_all_columns", # Other options: append_new_columns, ignore, fail
)
}}
SELECT * FROM {{ ref("schema_shifting_data") }}
{% if is_incremental() %}
WHERE ts > (SELECT ts FROM {{ this }} ORDER BY ts DESC LIMIT 1)
{% endif %}
Summary
| Strategy | When to use | Description |
|---|---|---|
| smart | Most use cases, especially large datasets | Intelligent schema evolution without data movement; handles type reconciliation automatically |
| sync_all_columns | Ensure target tables always reflect current source structure | Synchronizes target schema to exactly match source, adding new columns and removing obsolete ones |
| append_new_columns | Preserve historical columns while adding new ones | Adds new columns from source but keeps all existing target columns unchanged |
| ignore | Maintain existing schema without modifications | No schema changes are made; uses existing target schema regardless of source changes |
| fail | Need strict control over schema changes | Raises an error on any schema mismatch, forcing manual intervention |
| full-refresh | Making significant schema changes to ensure data consistency | Rebuilds entire dataset from scratch with updated schema |